03 Dec 2014
This post is the first in a series in which I’m going to describe various aspects of Cisco’s Application Centric Infrastructure (ACI). ACI, if you aren’t already aware, is a new DC network architecture from Cisco which uses a policy based approach to abstract traditional network constructs (e.g. VLANs, VRFs, IP subnets, and many more). What I’m not going to do in these posts is cover too many of the basic concepts of ACI - for that, I recommend you read the _ACI Fundamentals _book on cisco.com, available here. Instead, my intention is to cover the practical aspects of building and running an ACI fabric, including how to bring up a fabric, basic physical connectivity and integration with virtualisation systems.
Before we start, it’s worth taking a look at the high level architecture of ACI. Here are the highlights:
-
ACI is based primarily upon two components: Nexus 9000 switches and Application Policy Infrastructure Controllers (APICs). The Nexus 9000 platform forms the physical switching infrastructure, while the APIC is a clustered policy management system responsible for all aspects of fabric configuration.
-
ACI uses a leaf and spine topology. A given leaf node is connected to all spine nodes in the fabric, with no connectivity between leaves or between spine switches. All server, host, services and external connectivity is via leaf nodes - nothing is directly connected to a spine (apart from leaf nodes, obviously).
-
ACI uses a policy model to define how applications and attached systems communicate. In addition, policies are used within ACI to define almost every aspect of system configuration and administration.
-
Several new constructs are introduced within ACI, including End Point Groups, Application Profiles, Contracts, Filters, as well as objects associated with external connectivity, such as Layer 2 and Layer 3 Outsides. I’ll be covering most of these in the forthcoming posts, but please have a look through the relevant sections of the ACI fundamentals book (linked to above) for more details.
-
ACI has the ability to integrate closely with L4 - L7 services devices using the concept of service graphs. A service graph is essentially a description of where a given service (e.g. a firewall) should sit in the flow of traffic. Configuration of the services device can also move directly to the APIC through the use of device packages.
-
All ACI fabric functionality is exposed through a Northbound REST API, with both XML and JSON supported.
Now that we’ve covered some of the basics, I’ll run quickly through what I plan for the rest of this blog series:
-
First things first: getting a fabric up and running. Bringing up a fabric for the first time is a relatively easy thing to do but I’ll run through how it’s done and some of the key information you’ll need to build a ‘bare’ fabric.
-
Once we have the fabric up and running, we’ll take a look at the APIC and familiarise ourselves with the overall look and feel, as well as running through the main sections (tenants, fabric, and so on).
-
We’ll then take a look at some of the major objects within ACI: Application Profiles, EPGs, Contracts and Filters. It’s important that these concepts are well understood, so I’ll examine these in more detail.
-
Next on the list: networking concepts such as contexts and bridge domains - and how they relate to each other.
-
Before we look at getting some real connectivity between hosts, we need to take a look at access policies - we use these to define physical connectivity into the fabric.
-
I’ll then bring everything together and show you how we get two hosts talking to each other through the fabric.
-
Further down the line, we’ll take a look at some other topics including external connectivity, integration with L4-L7 services and more!
OK, that’s enough talking - let’s get going! Part 2 is here.
02 Dec 2013
It’s been a while since I posted - I’ve been spending a lot of time getting up to speed on the new Nexus 9000 switches and ACI. The full ACI fabric release is a few months away, but one of the interesting programmability aspects of the Nexus 9000 (running in “Standalone”, or NX-OS mode) is the NX-API. So what is it exactly?
The NX-API essentially provides a simple way to run CLI commands on one or more devices using a REST API. If you aren’t familiar with the term, a REST API exposes resources and services using well known HTTP methods (such as GET, POST, etc). To access the NX-API, we send an HTTP GET or POST request to a well known URL, for example _http:///ins_. We also need a way of passing actual data to the API - the NX-API expects to see input based on a simple XML string. Contained within this XML string are the commands you want to run.
**Getting Started
**
To get started with the NX-API, you first need to enable the feature on the switch. This is easy - it’s just like enabling any other NX-OS feature:
Nexus-9000(config)# feature nxapi
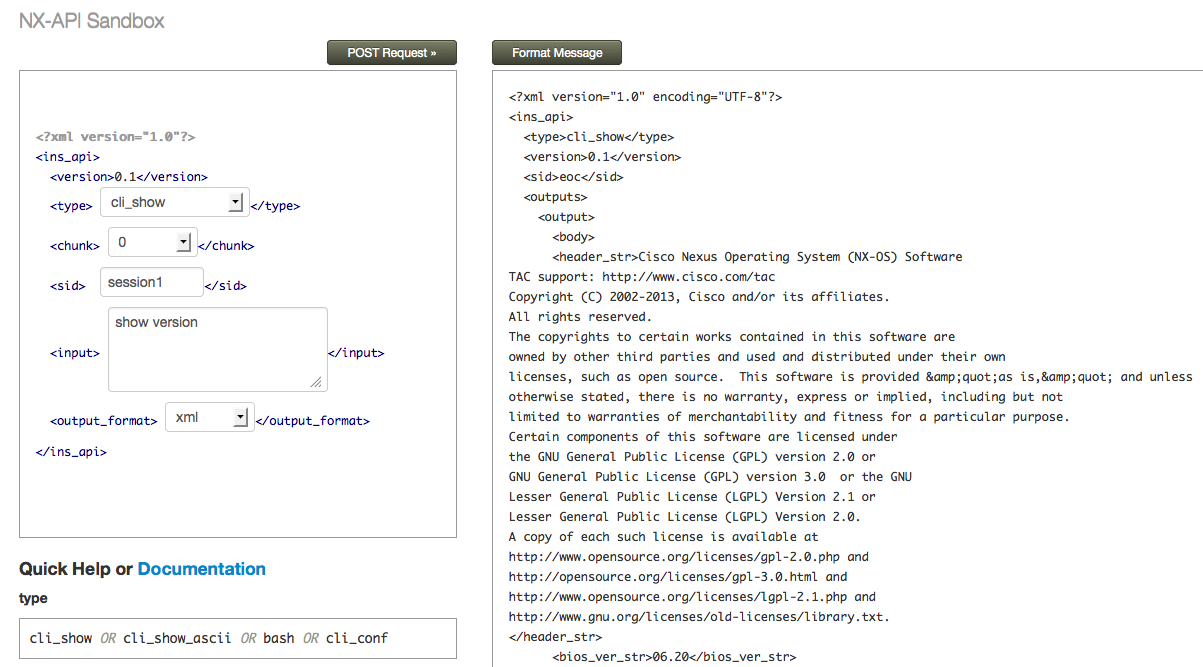
The best way to get up to speed with how the NX-API works is through the built in sandbox environment - this is a web-based interface that allows you to test commands and the resulting output. You can get to the sandbox simply by browsing to the management IP address of the switch:
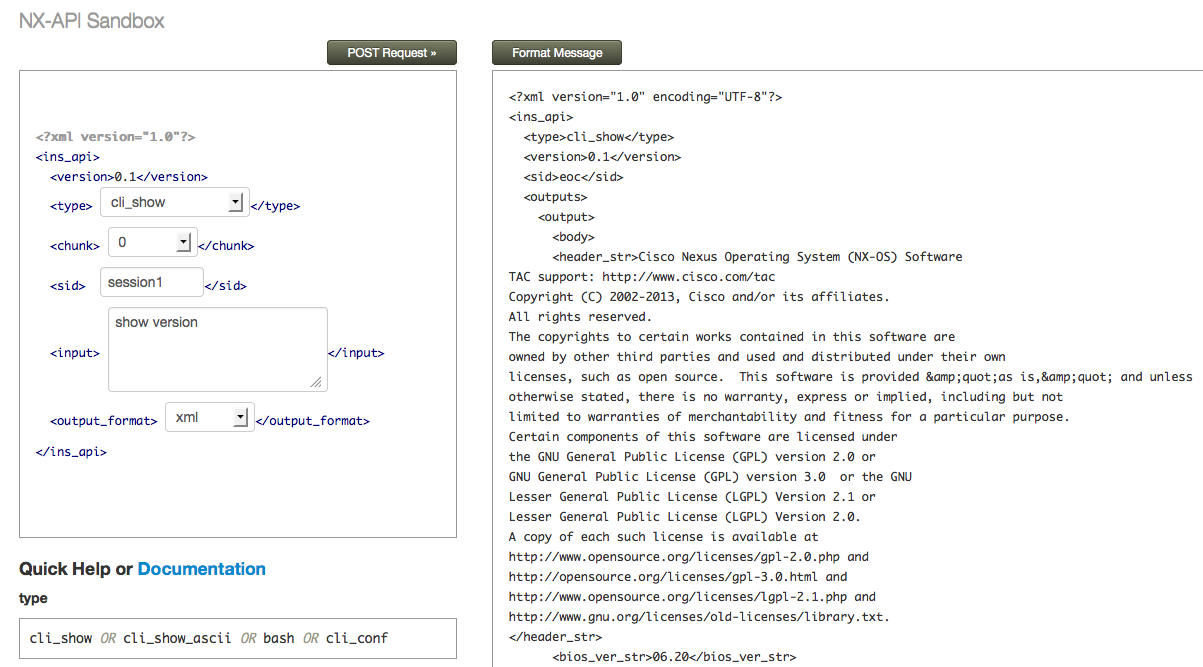
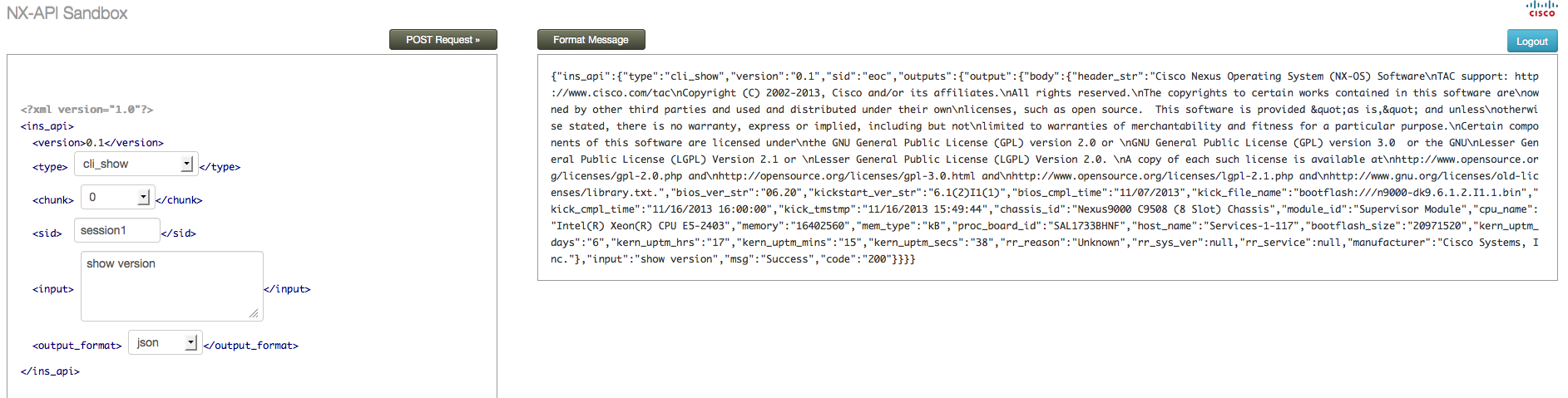
On the left hand side of the sandbox screen, you can select the type of command you want to send (more on that in a moment), the output format (XML or JSON) and the actual command you want to send (in the above screen we are sending “show version”). On the right, we can see the output of the command returned to us in XML format. What if you prefer the output in JSON format? No problem, you just change the output format:
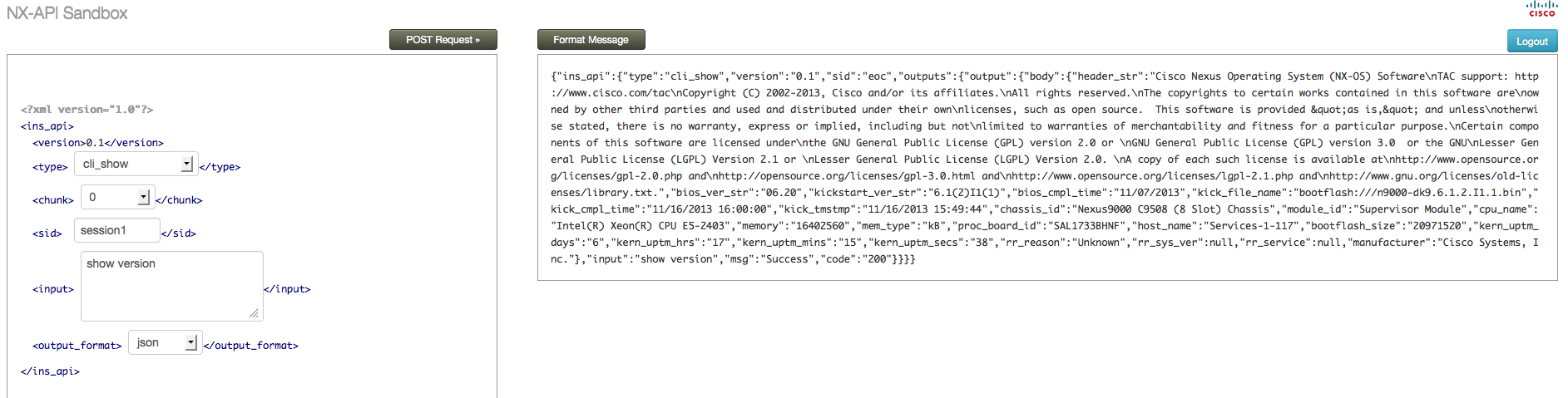
What input does the NX-API expect to see?
NX-API expects to see input that conforms to a simple XML format, as follows:
xml_string="<?xml version=\"1.0\" encoding=\"ISO-8859-1\"?> \
<ins_api> \
<version>0.1</version> \
<type>"cli_show"</type> \
<chunk>0</chunk> \
<sid>session1</sid> \
<input>"show version"</input> \
<output_format>xml</output_format> \
</ins_api>"
Let’s have a closer look at some of these fields:
Version: Always 0.1 at the time of writing.
Type: There are several command types that can be executed through the NX-API. I’ll explain these below.
Input: The actual NX-OS CLI command that you want to send to the device using the API.
Chunk: If this field is set to 1, the output should be ‘chunked’. This might be necessary if the output of a command is long - in that case, chunks of the output can be sent back to the client as they are ready.
Command Types
As mentioned above, there are a number of command ‘types’ available for sending show and configuration commands to a device using the NX-API. Which type you need to use depends somewhat on the actual command you want to send:
| _cli_show: _You should use the “cli_show” type when you want to send a show command that supports structured XML output. How do you know whether a command supports XML output? If you go to the CLI of the switch and run the command with the “ |
xml” option on the end, you’ll be able to see whether that command returns XML output or not. What happens if you try and use the “cli_show” command type with a command that doesn’t support XML? You will receive a message stating “structured output unsupported” from the API: |
<code id="responseMsg"><?xml version="1.0" encoding="UTF-8"?>
<ins_api>
<type>cli_show</type>
<version>0.1</version>
<sid>eoc</sid>
<outputs>
<output>
<input>show clock</input>
<msg>Structured output unsupported</msg>
<code>501</code>
</output>
</outputs>
</ins_api></code>
If that happens, you’ll need to use the second command type - “cli_show_ascii”.
cli_show_ascii: This command type returns output in ASCII format, with the entire output inside one <body> element. Any command on the switch (including ones that don’t support structured XML output) should work with this command type, although it will be more difficult to parse compared to those commands that return XML.
_cli_conf: _Use this command type when you want to send configuration commands (as opposed to show commands) to the API.
**bash: **You can use this command type if you want to send Bash shell commands to the device through the NX-API.
Authenticating to the NX-API
In order to use the NX-API, you must first authenticate to the device. This can be done using basic HTTP authentication - the client should send the username and password to the device using the HTTP authorisation header. The first time the user authenticates, the device will send back a session cookie (named nxapi_auth). This session cookie should be sent in subsequent requests to the NX-API (along with the credentials) to reduce the load on the authentication module on the switch.
Hopefully this gives you an overview of what the NX-API does. Although the design of the API has been kept intentionally simple, there are a large number of potential uses and it should prove a useful tool for managing the network environment. Thanks for reading.
23 Aug 2013
One of the interesting design considerations when deploying FabricPath is where to put your layer 3 gateways (i.e. your SVIs). Some people opt for the spine layer (especially in smaller networks), some may choose to deploy a dedicated pair of leaf switches acting as gateways for all VLANs, or distribute the gateway function across multiple leaves. Whatever choice is made, there are a couple of challenges that some have come across.
As you may know, vPC+ modifies the behaviour of HSRP to allow either vPC+ peer to route traffic locally. This is certainly useful functionality in a FabricPath environment as it allows dual active gateways, however what if you want your default gateways on the Spine layer (where there are no directly connected STP devices, and therefore no real need to run vPC+)? What you end up with in this case is vPC+ running on your Spine switches in order to gain access to the dual active HSRP forwarding, but with no actual vPC ports on the switch. This works fine - but most people would prefer not to have vPC+ running on their Spine switches if they can avoid doing so.
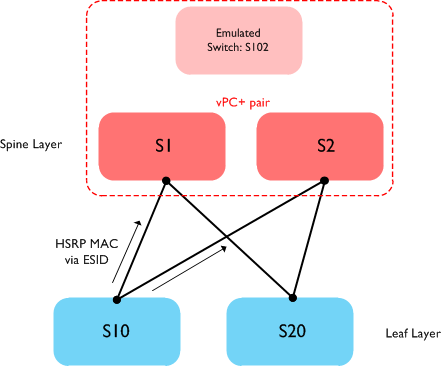
The other drawback of using vPC+ is that you can only have two active gateways - only HSRP peers in ‘active’ or ‘standby’ state will forward traffic, with peers in ‘listening’ state unable to forward. So in larger FabricPath networks where you have multiple Spine switches, lots of bandwidth, many different layer 2 paths, etc, you are still limited to two active L3 gateways.
As of the NX-OS 6.2(2) release, there is a new option - Anycast HSRP. Essentially, this feature allows you to run multiple active first-hop gateways without the use of vPC+, as well as provide a higher number of active forwarders (currently 4). So how does it work?
When you configure vPC+, you use an Emulated Switch ID to represent both peers to the network - this switch ID is configured on both peers and other FP switches on the network use that ESID to reach MAC addresses (including the HSRP VMAC) behind the two switches. With Anycast HSRP, a similar concept is used, known as the Anycast Switch ID (ASID). This is for all intents and purposes identical to the vPC+ Emulated Switch ID, except that a) you don’t need to configure vPC+ and b) it works across more than two switches. To configure an ASID, we use a new type of configuration on the switch - the HSRP bundle. The configuration looks like this:
hsrp anycast 1 ipv4
switch-id 102
vlan 10,11,12
priority 120
no shutdown
Once you have added the bundle configuration, it then needs be tied to an interface:
interface Vlan10
hsrp version 2
hsrp 1
ip 1.2.3.4
Note that HSRP version 2 must be configured on the interface for Anycast HSRP to work.
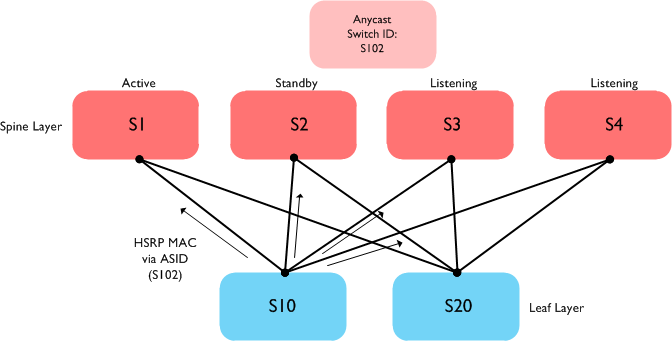
Let’s say we now have four spine switches in our network and want to run HSRP across all four of them. The resulting topology looks like this:
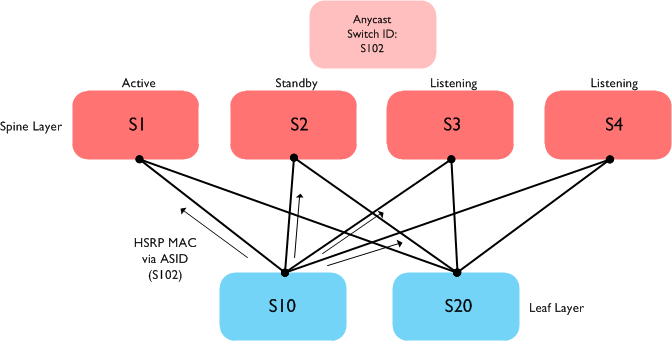
In the above scenario, the two leaf switches (S10 and S20) learn that the HSRP VMAC is accessible via the switch ID S102 (the Anycast switch ID). FabricPath IS-IS then calculates that this switch ID is accessible via any of the spine switches (S1, S2, S3 or S4). Note also that all four spine nodes (even the ones in HSRP listening mode) are actively forwarding L3 traffic.
Note that there is one important consideration when using Anycast HSRP - all switches must be running Anycast HSRP capable software. So in our example above, we must also be running an Anycast HSRP capable image on the leaf switches (S10 and S20) as well as the spines. In many networks, the leaf switches will be Nexus 5500 / Nexus 6000 switches; support for Anycast HSRP will be coming to those platforms in a future release.
24 Jun 2013
VXLAN (Virtual eXtensible LAN) is an ‘overlay’ technology introduced a couple of years ago to solve the challenges associated with VLAN scalability and to enable the creation of a large number of logical networks (up to 16 million). It also has the benefit of allowing layer 2 segments to be extended across layer 3 boundaries due to the MAC-in-UDP encapsulation used.
One of the most significant barriers to the deployment of VXLAN is its reliance upon IP multicast in the underlying network for handling of broadcast / multicast / unknown unicast traffic - many organisations simply do not run multicast today and have no desire to enable it on their network. Another issue is that while VXLAN itself can support up to 16 million segments, it is not feasible to support such a huge number of multicast groups on any network - so in larger scale VXLAN environments, multiple VXLAN segments might have to be mapped to a single multicast group, which can lead to flooding of traffic where it is not needed or wanted.
With the release of version 4.2(1)SV2(2.1) of the Nexus 1000V, Cisco have introduced ‘Enhanced VXLAN’ - this augmentation to VXLAN removes the requirement to deploy IP multicast and can utilise the VSM (Virtual Supervisor Module) for handling the distribution of MAC addresses to each of the VEMs (Virtual Ethernet Modules). This post will delve into the specifics of enhanced VXLAN and explain how the various modes work.
**Head End Replication
**
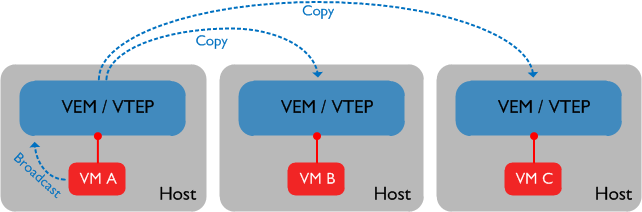
The first thing to understand about enhanced VXLAN is that there are two unicast modes in which the feature can run: “Flood and Learn” mode, or “MAC Distribution” mode (also known as “Floodless” mode). We’ll discuss the differences between these modes in a bit, but the most important point about both of these is that for broadcast and multicast traffic, the VTEP (VXLAN Tunnel End Point) where the source VM resides will perform head-end replication to the other VTEPs that have VMs residing in the same VXLAN / segment. This essentially means that the sending VTEP will replicate the broadcast or multicast packet locally and send it to all hosts participating in the VXLAN in question. Let’s look at an example of this:
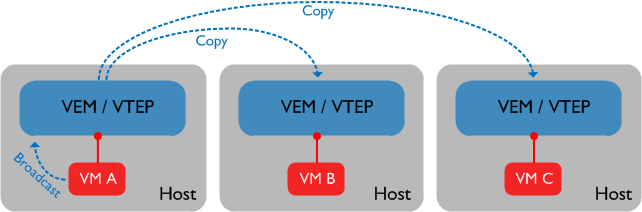
In the above example, all VMs reside in the same VXLAN. VM A sends a broadcast packet which reaches the local VEM / VTEP. In the original release of VXLAN, the VTEP would use the underlying IP multicast transport to ensure the broadcast packet reaches each of the VTEPs. With enhanced VXLAN, we are replicating the packet locally and sending a copy of the packet directly to the other VEMs / VTEPs. Note that if there were another host containing VMs not in our VXLAN, the broadcast packet would not be sent to that VTEP.
What about unknown unicast traffic? How we handle this type of traffic depends on which unicast mode we are operating in, which leads us to the next section.
Unicast “Flood and Learn” Mode
The first of the unicast modes is “Flood and Learn” mode; in this mode, we use head-end replication as described above to ensure that broadcast and multicast packets reach their destination, thus doing away with the requirement for IP multicast in the underlying transport network. However, in this mode we continue to learn MAC addresses via the “flood and learn” method - essentially nothing has changed in terms of how we learn MACs on our VEMs / VTEPs. For example:
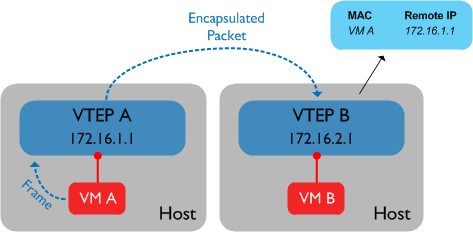
When VTEP B receives the encapsulated VXLAN packet from VTEP A, it decapsulates it and learns that the address of VM A lives behind VTEP A (172.16.1.1). This is identical to how we learn MACs with the ‘original’ version of VXLAN.
What about unknown unicast traffic? In “Flood and Learn” mode, if a unicast packet needs to be switched but no entry is found in the MAC table, we will use head-end replication (just as we do for broadcast / multicast) to ensure that the packet reaches all the other VTEPs that contain VMs residing in the relevant VXLAN segment.
In ‘non-enhanced’ VXLAN, a VTEP would send out broadcast / multicast / unknown unicast frames using a specific multicast group in the transport network, safe in the knowledge that the frames would be delivered to every VTEP participating in the relevant VXLAN segment. So in unicast mode, how does a VTEP know where to send the locally replicated packets once they are encapsulated? In both of the unicast modes, the Nexus 1000V VSM keeps a record of all VTEPs operating within any given VXLAN segment and distributes this information to all the VEMs within the domain. We can see this on the VSM by running show bridge-domain vteps, e.g:
N1KV-VXLAN# show bridge-domain test-vm vteps
D: Designated VTEP I:Forwarding Publish Incapable VTEP
Bridge-domain: test-vm
Ifindex Module VTEP-IP Address
------------------------------------------------------------------------------
Veth3 3 172.16.1.1(D)
Veth4 4 172.16.1.2(D)
Enabling Unicast Flood and Learn mode is simple: in the global configuration, use the command ‘segment mode unicast-only’.
But what if we don’t want the traditional flood and learn behaviour in our VXLAN environment? Can’t we use a control plane mechanism to distribute MAC address information throughout the domain? Look no further than the second unicast option in Enhanced VXLAN: MAC Distribution mode.
Unicast “MAC Distribution” Mode (AKA “Floodless” Mode)
In MAC Distribution mode, we still use head-end replication to deliver broadcast and multicast frames to the rest of the network. However in this mode we do not perform MAC learning based on data plane activity; instead we use the central control functionality of the Nexus 1000V - the Virtual Supervisor Module, or VSM - to keep track of all MAC addresses in the domain and disseminate that information to the VEMs / VTEPs on the system. Let’s take a look at how this is achieved.
The first step in the learning process begins with all the VEMs / VTEPs becoming aware of the MAC addresses that are connected locally. This happens automatically when a virtual machine is powered up; locally connected MACs are installed in the VEM as ‘static’ entries. Once this has taken place, the next step is for the VEMs to report these statically installed MAC addresses to the VSM. We can check that this has taken place by using the command ‘show bridge-domain mac’, as shown in the following example:
N1KV-VXLAN(config)# sh bridge-domain test-vm mac
Bridge-domain: test-vm
MAC Address Module Port VTEP-IP Address VM-IP Address
------------------------------------------------------------------------------
0050.5699.1bc3 3 Veth5 172.16.1.1 -
0050.5699.3e45 4 Veth6 172.16.1.2 -
In the above output, we can see that the VSM is aware of two MAC addresses and is keeping track of which VEM / VTEP each one sits behind.
Finally, the VSM must distribute the MAC information to each of the VEMs / VTEPs - the VSM will ensure that the latest version of the MAC table is available to all VEMs. On the VEMs, the MAC entries that have been received from the VSM will be programmed as ‘software installed’. It is possible to see these entries directly on the VEM modules using the following command:
~ # vemcmd show l2 bd-name test-vm
Bridge domain 9 brtmax 4096, brtcnt 2, timeout 300
Segment ID 5000, swbd 4096, "test-vm"
Flags: P - PVLAN S - Secure D - Drop
Type MAC Address LTL timeout Flags PVLAN Remote IP
SwInsta 00:50:56:99:3e:45 561 0 172.16.1.2
Static 00:50:56:99:1b:c3 51 0 0.0.0.0
In the above output, the first entry in the list is a software installed MAC which has been sent to this VEM by the VSM. The second entry in the list is a locally connected MAC address (installed statically).
Remember earlier I said that unknown unicast traffic was handled differently depending on which unicast mode is in use? In MAC Distribution mode, it is assumed that if a MAC address exists on a VEM, it will be distributed to all VEMs through the MAC distribution mechanism. Because of this, there should be no unknown unicast MAC addresses anywhere within the VXLAN. What there might be however, are unknown unicast addresses residing outside of the VXLAN - in other words, accessible via a VXLAN gateway. So, if a MAC entry is not found in the table when a unicast packet is being switched, the local VEM / VTEP will send that packet only to any VTEPs designated as VXLAN Gateways (technically these are referred to as ‘Forwarding Publish Incapable VTEPs) - it will not send the unknown unicast packet to every VTEP (as is the case in unicast “Flood and Learn” mode).
There are also plans to further enhance VXLAN using a BGP based control plane - this will allow VXLAN to scale out across two or more Nexus 1000V systems. This is being demonstrated at Cisco Live in Orlando this week - more details here.
Thanks for reading!
Static 00:50:56:99:1b:c3 51 0 0.0.0.0
22 May 2013
A question that I still get quite a lot is how to connect Nexus 2000 Fabric Extenders to their parent switches - is it better to single attach them to the parent, or to dual-home the FEX to both parent switches (using vPC)? Of course there is no right answer for every situation - it depends on the individual environment and sometimes personal preference, but here are a few of my thoughts on this.
We can dual home the FEX to the parent Nexus 5500 - that must be better, right?
This is a fairly common line of thinking - many people assume dual homing is automatically better than single homing, but that’s not necessarily always the case. The best question to ask is what failure scenario you are trying to protect against, and where the recovery will happen (within the network or at the host level). For example, if you are trying to guard against the failure of a single Nexus 2000 Fabric Extender, then dual homing that Fabric Extender to two parent switches will clearly not help you - you need to ensure that hosts / servers are dual homed to two Fabric Extenders to mitigate this risk.
Dual-homing Fabric Extenders using vPC does give you some protection against the failure of a single Nexus 5000 parent switch - if that happens, the FEX still has connectivity to the second parent 5K, so the host ports remain up and hosts should not see any interruption. This is particularly helpful in a situation where there are single attached hosts - these hosts have no other protection against the failure of a parent switch, so this is one situation where dual-homing of FEXs might make sense. Although it is stating the obvious somewhat, it’s worth pointing out here that if you have single attached hosts there is still a single point of failure (i.e. the FEX itself could fail), so it’s always a better idea to dual-home hosts to the network in the first place.
Why would I not want to dual-home my Fabric Extenders?
Dual-homing a Nexus 2000 to its parent switches brings some challenges compared to single attaching. Firstly, it is necessary to configure host ports residing on the FEX from both parent switches - in other words, the configuration for the ports in question needs to be kept synchronised across the two parent switches. Of course you can do this manually, or use the config sync feature but in general there is some management overhead with maintaining this. Another downside is that you effectively cut the number of FEXs you can support by half when you dual-home.
What about connecting Fabric Extenders to the Nexus 7000?
If you are connecting Nexus 2000s to Nexus 7000 parent switches, then you have no choice (at the time of writing, May 2013) - dual-homing of FEXs isn’t currently supported. I’ve heard some people complain about the lack of support for this on the 7K, but in reality it goes back to what you are trying to protect against. Given that we have already established that dual-homing of a FEX helps to protect against a failure of one parent switch, how often do you expect to lose an entire Nexus 7000 (considering it usually has redundant Supervisors, Fabrics, Linecards, etc)? That should (hopefully) be quite a rare event - but if the worst does happen and you lose one of your 7Ks, as long as your hosts are dual-homed, they should fail over to the remaining 7K / 2K using whatever teaming / port-channelling method is in place. Support for dual-homing FEXs to Nexus 7000s may come in the future, but my opinion is that not having it today is no great loss.
The bottom line is that dual-homing of Fabric Extenders to Nexus 5000 parent switches might give you some benefit in a scenario where it is not possible to dual attach hosts / servers to the network - however I would question the importance of those servers if that is the case. If you dual attach all your hosts to two Fabric Extenders (which you should), then FEX dual-homing gives you quite a limited benefit in my view.